I attended AgileDC this week. I hadn’t planned on it, but at the last minute we got as nudge at work that our new GrandBoss was encouraging people to attend, so I shuffled my scheduled and went in. I’m very glad that I did. It’s a one day event, filled with 45 minute talks and well thought out breaks. I love the 45 minute format – it means fewer deep dives, but it also demands that speakers cut the fat from their decks and really focus in on the key of their point. As an aside, it also means that time-filler workshop activities must be kept to a minimum out of sheer necessity, and I am always up for that.
I had a number of takeaways from the event, but my favorite (and the one I’m itching to use) is a method of handling estimation which was rooted in my misunderstanding a speaker explain the bucket method.
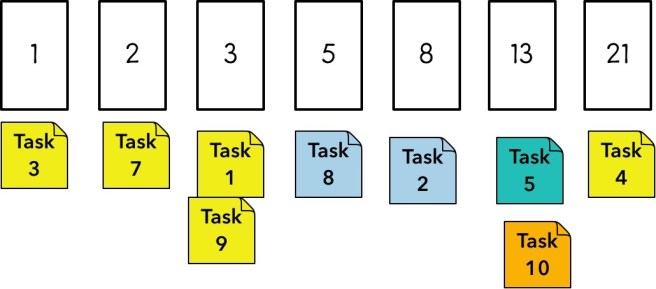
For the unfamiliar (as I was) the method is a simple relative sizing tool that’s good with larger groups. Set up an empty table with a number of columns (these are the ‘buckets’) labeled according to your sizing schema – let’s go with fibonacci for simplicity. Grab the first ticket and simply put it at the middle, say, at 5.

Then, grab the next task, and rather than get into a long discussion of the “right size”, you simply ask “is this bigger, smaller, or about the same size as the last on? If it’s bigger, put it to the right, if it’s smaller, put it to the left. If it’s the same size, put it underneath.
Over time, you’ll fill in multiple columns, but the decision making process will be roughly the same – if the new task goes between two tasks, slide them apart and put it in there. At the end, you have a sorted, pointed list without anyone needing to have an argument about what a 5 “really means”
So, this is great, and I would love to try it, but the secret sauce was the part I misunderstood. For whatever reason, I missed the part where you label the buckets beforehand, so as I understood it, you just built the stack and then assigned the numbers based on how they shook out (so the leftmost is now 1).
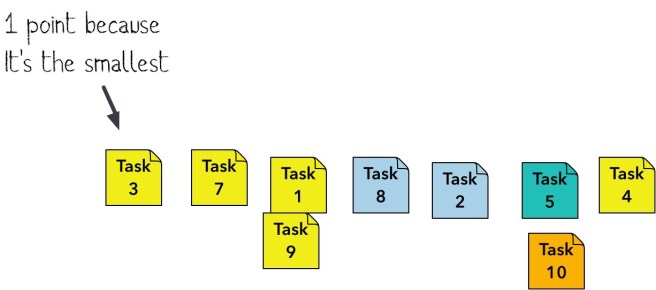
I love this. It’s the estimation equivalent of building sidewalks to follow the grass worn by pedestrian traffic.
It has some risks – too few columns might result in inconsistent sizing (which can throw off velocity calculations) and too many might break the estimation schema (which is not automatically bad, but is probably a sign that your team is being a bit too granular).
So with that in mind, I think what I intend to try is somewhere between the original and my lack of understanding. I’ll keep the same 7 buckets (because I like 7 a lot of brain things) but I won’t label them the first time, and I’ll start in the middle.
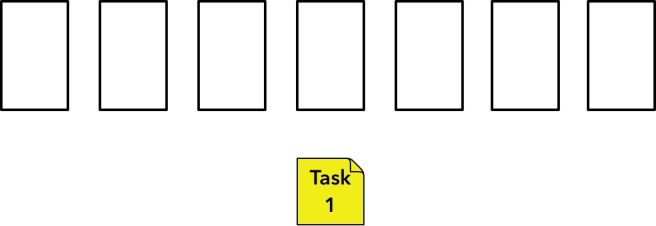
This way, as a team, we will *find* what a 5 (or whatever) is for us. After a few rounds (or maybe even just one, if it goes well) if we have some agreement on an anchor point, then we can just start there and proceed.
Now, I haven’t tried this yet, though I may have an opportunity to soon. It’s exactly the sort of experiment I’m very excited to try.

Nice. I’ve used bucket sizing before, but I’ll definitely give your labelless variant a try.
I uses the planning velocity exercise as a cross check for this. I ask the devs to put the stories into 4 or 5 “we can do these in a week” sized chunks, without looking at the points written on the back. If the chunks are roughly the same size, that’s our planning velocity. (It’ll be wildly wrong, of course, but until you have yesterday’s weather to work from, everything will.) If the chunks are wildly different sizes, something hjs gone wrong…